This post is part of a series “The Quest for General Artificial Intelligence”. To access the index for this series click here.
In the previous blog posts we introduced changes to the way the Environment is considered and how the observations and the state estimations are processed by the Agent. This time we will consider how the rewards are evaluated, and in comparison to the standard Reinforcement Learning models this change is the most dramatic and possibly the one that will produce the most profound alterations in the behaviour of models based on RL.
Rewards are the defining element in RL and they play a crucial role in determining the correct policy. They are not only used to calculate the expected return for the task at hand, but changes in the way these rewards are provided and how they are discounted can produce significant variations in the learning process.
This brings us to a crucial question: who decides what value these rewards should be? This is probably the weakest point of RL and very often the choices made by researchers and developers (or competition initiators for that matter) seem to be arbitrary. Why a certain reward per time step is -0.1 while if the task is completed successfully is 10.0? And why should a discount factor be 0.9 or 0.95? Surely this seems artificial and reeks of God syndrome.
If we take the case of an actual individual that performs actions in a given environment, what can constitute a reasonable assumption relative to the value of reward that the individual should receive at every time step? Is it reasonable to expect that this reward would be same for other individuals? Or even, for the same individual, to expect the rewards to be the same at different times or in different contexts?
When Sutton and Barto introduce the concept of reward in [1] they specifically indicate that this is a function that sits outside the Agent:
“The reward function defines what are the good and bad events for the agent. In biological systems, it would not be inappropriate to identify rewards with pleasure and pain. They are the immediate and defining features of the problem faced by the agent. As such, the reward function must necessarily be unalterable by the agent. It may, however, serve as a basis for altering the policy.” [1] pp. 7-8 (my emphasis).
And later:
“Rewards, too, presumably are computed inside the physical bodies of natural and artificial learning systems, but are considered external to the agent.” Idem pp. 53
In [2] Legg and Hutter attempt to provide a more rational reason why rewards should be kept outside of the Agent:
“Strictly speaking, reward is an interpretation of the state of the environment. In humans this is built in, for example, the pain that is experienced when you touch something hot. In which case, maybe it it should really be part of the agent rather than the environment? If we gave the agent complete control over rewards then our framework would become meaningless: The perfect agent could simply give itself constant maximum rewards.” [2] pp. 5 (my emphasis).
It is interesting to note that above authors refer to the pleasure / pain mechanisms in humans as being one form of manifestation of reward, a function that is obviously internal to the Agent. I will argue that in addition to these primitive reward mechanisms, that are potentially hard to control and operate at a conscious level, there are multiple layers of rewards that are under Agent’s control and can offset these primitive reward systems.
Example 1:
Everyone that has used a gym knows the saying “No pain, no gain”. There is obviously significant pain (negative reward) that is produced during intensive physical activity, but this does not stop the majority of people to persist in their workout. There are additional layers in the frontal cortex that seem to identify longer-term rewards and issue corresponding positive signals that offset the previous negative ones. It is interesting to notice that there seem to be a mechanism in the brain that “spins” the negative message related to the physical pain and converts it in a confirmation that “I’m doing something good if I feel this pain”.
Example 2:
One of the most primitive control mechanisms in living beings is to survive. It is virtually impossible to stop breathing or to stop your heart beating. Still there are ways, through the actions one may take, to work against these basic functions. Apart from the obvious cases of suicide and self-harm, this also leads to actions of sacrifice on behalf of others or risk taking for a higher goal. It is easy to point to high risk behaviour in human history, predicated on the possibility of vast (but unknown) reward, such as travelling to the poles or the highest peak, etc.
There is something that defines the reward values inside each of us and it is unique. Our Agents would also need to have this capability if we genuinely want to have them express General AI. We will therefore consider that the reward is a measure that is internally determined by the Agent from the information received from Environment, specifically 

Here we used the state estimate from the previous time step to indicate that the determination of the reward and the re-evaluation of the state happen simultaneously, although it is also possible to represent them as part of a pipeline process, being produced sequentially. To stay consistent with the rest of notations I also used the hat for the value of reward, indicating the fact that it is an estimate (the Agent’s expectation of reward).
In the figure bellow we have extend the model for GAI by incorporating the derivation of the reward evaluation in the agent:
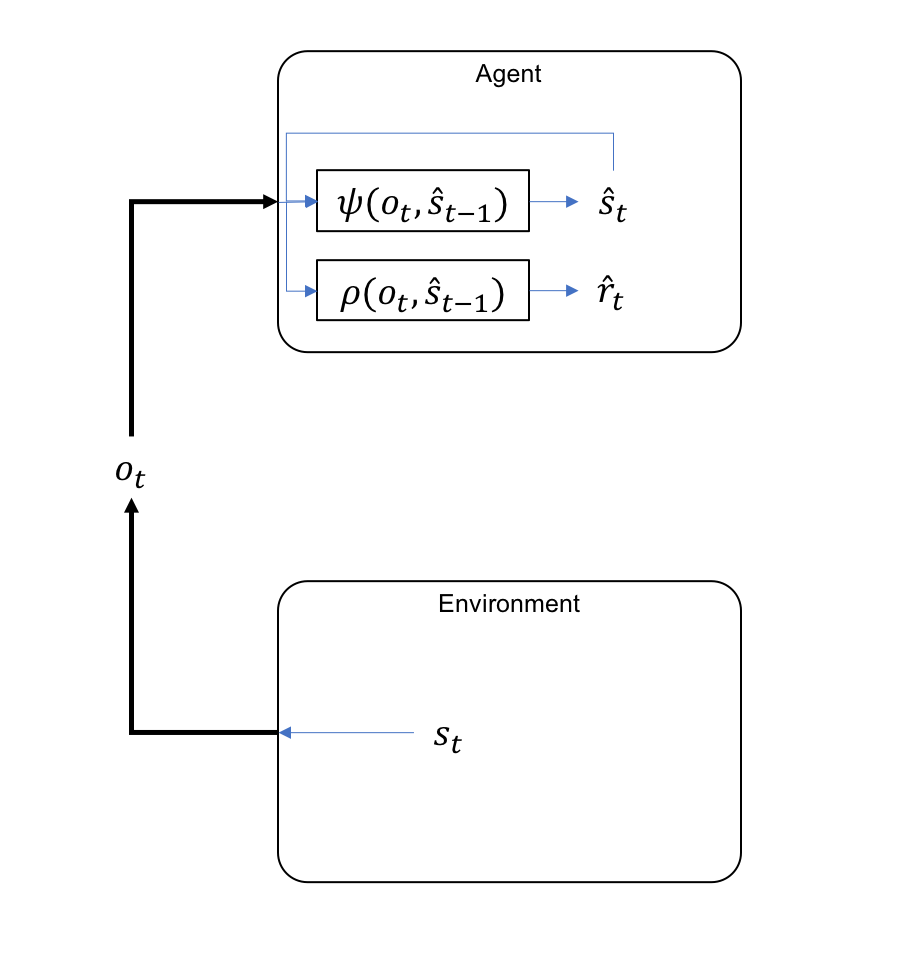
This change, apparently minor, has significant consequences for the RL model:
- We no longer need arbitrary rewards as part of the training process
- Each agent could develop its own reward function and in turn learn and apply different policies for action determination; Agents become individuals
The reward function employs dynamicity: if in Classical Reinforcement Learning (CRL) rewards remain constant for the same state transitions (as defined by the MDP model) in General Reinforcement Learning (GRL) the Agent might reduce the value of the same reward in a process of diminishing impact of a particular transition. It is important to notice that this decaying of the reward evaluation is different from the concept of discounted reward from CRL where is applied to the expected future values, while in our case is a reflection of reduction the current reward experienced. As a matter of fact, I will argue later when I will introduce prediction in the model, that the reward is nothing but a measure of the surprise factor (positive or negative) in respect with a particular expectation for a state transition. As the agent is getting better at attaining the expected state transitions, the surprise factor decreases, and rewards diminish in value.
Example 3:
There seems to be a common pattern of behaviour that similar inputs trigger a diminishing reward evaluation over time, as if they are subject to a form of de-sensitisation. This explains why we never seem to be satisfied to be part of a repetitive activity for long periods of time no matter how rewarding they seemed in the beginning.
A further implication of the above is related to the delayed reward, a situation that makes the training very slow and time consuming, sometimes even leading to lack of convergence in training. In a way I am of the opinion that these situations are constructed artificially and are not a reflection of the way the brain operates, as shown in the next example.
Example 4:
We can have a model where the agent needs to play table tennis and a positive reward is available only when the agent has won a point (or even harder when a whole match has been won). No additional rewards are provided in the rest of the periods, making it very hard for the model to correctly evaluate a particular good action. This type of problem is subject to extensive research and it considered a very difficult problem in the current RL landscape. But I personally consider this a false problem and I do not think that delay rewards actually exist in nature. If we think about how an individual will actually tackle this problem, we will realize that it will be broken down hierarchically in smaller objectives. We will first just aim to hit the ball with the paddle and any successful attempt will be rewarded by our internal reward function. But as we get more skilled in hitting the ball the reward value will decrease (as we have seen in the previous example due to de-sensitization): we already have higher expectations that we will hit the ball and as a result there is less reward every time we perform that activity successfully. We now aim to hit the ball so that it lands on the table in the opponent’s side. Successful attempts to do this will again be evaluated highly by the reward function, while the fact that we hit the ball in itself will lose most of the reward: it is a given that we hit the ball. It’s only when we completely miss the ball that previous reward function will still kick into place and penalise by issuing a negative reward: we were expected to hit the ball but missed it. Once we become skilled in putting the ball in the opponent’s side, this activity starts to lose the reward value; time to put the ball in the place we want on the opponent side, to make it harder for him to return it. After that comes the reward for winning the point, then winning the set and finally the match.
What we have seen in the example above is that the ultimate reward (winning the game) is decomposed hierarchically and each of the layers starts with very low expectations that, due to random experiences, incur episodically positive rewards. This leads to reinforcement of that particular state transition (action) and its expectation. As the activities produced by this lower layer become more and more effective, the chances that the higher layers also experience positive rewards increases and this propagates up the hierarchy.
As we will see later, this reward evaluation does not have a “place” in the brain, instead it is distributed at all levels and manifests through the prediction / error mechanism that we will introduce later.
References
[1] Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction. Adaptive Computation and Machine Learning. Cambridge, Mass: MIT Press, 1998. 322 pp. isbn: 978-0-262-19398-6
[2] Shane Legg and Marcus Hutter. “Universal Intel- ligence: A Definition of Machine Intelligence”. In: (Dec. 20, 2007). url: https://arxiv.org/abs/ 0712.3329v1.
This post is part of a series “The Quest for General Artificial Intelligence”. To access the index for this series click here.
