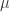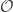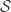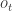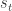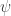AlexAIComments Off on GAI: Observations and State Representations
This post is part of a series “The Quest for General Artificial Intelligence”. To access the index for this series click here.
We continue our quest for General AI. In the last post we expanded the Environment to represent the whole Universe and we introduced the main goal of the Agent as solving , the transition function we hypnotised to describe the evolution of .
This change has generalised the scope of our Agent but presented us with a problem: we cannot use as the input for our Agent as its dimensionality will make the processing in the Agent impossible. We will then introduce the term Observation to describe the information that the Agent receives from the Environment and we aim that the dimensionality of is much lower than while the state space has a much lower cardinality than the state space :
and:
The concept of “observation” is not something new, often in the RL literature it is used interchangeably with the term “state”, sometimes confusingly continuing to use the notation for state but referring to it as observation. In this model we will reserve the term “state” for the representations of the Environment while the exchange of information between the Environment and Agent will be referred to as “observation” .
The notion of observation should be very natural and would represent all sensory information that the Agent is capable of. If the Agent is a human, the observation space will describe all possible combination of visual, auditory, tactile, olfactory and gustative inputs. If the Agent is a robot, it will be dependent on all the sensors available to it (cameras, LIDAR, microphones, etc.). One important aspect to note is that while we consider the observation space fixed for a given Agent (i.e. the capabilities of that Agent cannot change), this does not limit the Agent in its ability to represent the Environment. This is an important aspect of our quest for General AI, as changing the Problem does not require to change the Agent. We will discuss this a little bit later in this post.
Within the Agent the observations will be processed with a state estimation function that will produce an internal representation of Environment’s state :
with representing a function that produces this internal representation.
It is very important to note that the state estimation function is a recurrent function, using not only the observations, but also the previous state estimation (). This will be a recurring (pun intended) pattern in this General AI model and we will discuss later the biological similarities with the human cortex as well as the complexities resulted for the actual implementation of these functions. You might have noticed too that the function only looks one step back in the history and only uses current observations. In principle the function can be dependent on the full history of and as in:
This would prove to be prohibitively expensive for the Agent to remember and we will make the assumption (extensively used in the classical RL [1]) that the internal state representation respects the Markov Property, meaning the current state includes all information needed from its history. That does not mean that the Environment state also has the Markov Property.
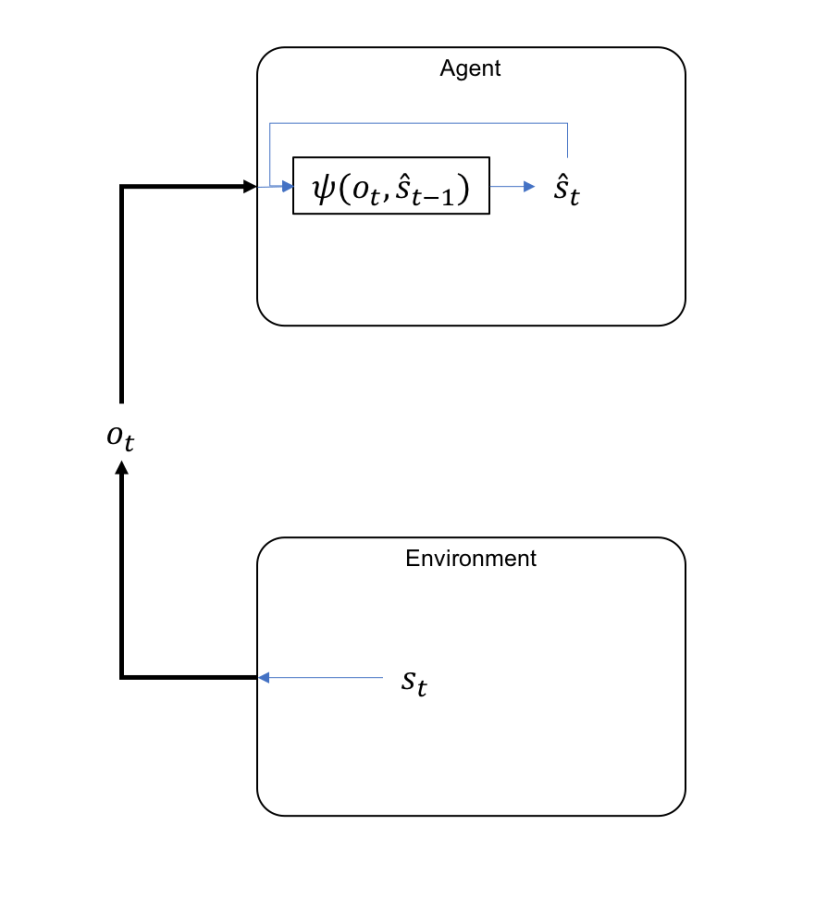
The relation between the Environment and the Agent can therefore the represented as follows:
Fig 1: Observations and State Representation
One way to look at the diagram above is by considering that the information related to state is selectively interrogated through the observations and represented internally in the Agent as . In a way is an inverse of a classical information channel: normally the encoded information is passed through the channel and then decoded on the receiver. Here the Agent has the ability, through the actions he can perform, to focus its observations , to sample the state information on those aspects that provide the maximum information for the refinement of the current state representation .
While observation has a much lower dimensionality than the environment’s state, we will argue that the Agent will be able to still infer any arbitrary state complexity, given enough time to process the information and a sufficiently large model capable to encode .
Example 1: According to the Newton third law of motion there is an equal reaction for every action between two bodies that interact. That means when I stand up a force equal to my weight is exercised by the floor upon my soles. I can use a measuring device to examine these and I will make a representation of the situation that includes the measures of my weight and the corresponding reaction force in the representation of the state space . In the Environment there might be something that represents the two forces in , but they might be completely different from the representation that I have. The concept of “force” is a representation of a pattern that we identified in the Environment and might only be a reflection of an even more elementary property that we are yet to identify and represent. But the important aspect here is that the representation of my weight and the force of reaction in and the corresponding representation of the associated concepts in are equivalent and, probably even more important, the dynamics of as determined by is reflected in the dynamics of as determined by .
Example 2: For a tennis ball in flight the state in might be represented through a series of attributes that describe the position, velocity, acceleration, spin, etc. An Agent, through a first observation can determine the position of the ball, then through a second observation refine the position and derive the velocity, possibly spin, etc. If the colour of the ball is not an information that has value for the task at hand the Agent can discard it (although might be available in ).
As we will see later the way I see this process happening is not “bottom-up” where the observations simply feed-forward through the Agent’s model, but instead, through , there is an expectation (or prediction) related to the that is propagated “top-down” while the “bottom-up” information from confirms or contests this prediction. We will come back to this idea later when we will discuss the principles for the implementation of GAI in the Agent.
I will finish this post with the observation that the limitations of do not mean that the Agent cannot infer additional information in using tools, like in the following example.
Example 3: A human’s vision is limited to a certain range in the electromagnetic spectrum, but a human can use devices that are sensitive to other ranges (for instance infra-red) that are then converted to a visible spectrum. In this case the normal vision can produce a certain representation of . When we decide to use the infra-red tool there will be a contextual information that we are using a device, also represented in as it is part of the current state we experience. When we look at the image the device produces, although we technically use the same input for receiving the information, because the previous state includes the information about us using the infra-red tool (the context), we will be able to infer additional information in related to the object we are observing different from the ones inferred with the naked eye.
In the next post we will look at the way the rewards are handled in the new model.