This post is part of a series “The Quest for General Artificial Intelligence”. To access the index for this series click here.
In the previous post we briefly introduced the Reinforcement Learning (RL) framework and we listed a number of limitations that the current implementations suffer by design. Our goal is to remove these limitations so that the updated framework is general and scalable. We will start by looking at the representation of the Environment in the Classical Reinforcement Learning (CRL) model.
Over the years there have been many attempts to define “intelligence” in a formal manner, either from a psychological, computing or generalist perspective (for a very impressive collection please see [1]). The common features of these definitions, as indicated in [2], are:
- Is a property of an entity which is interacting with an external environment
- The intelligence is related to the ability of the agent to succeed in an environment. This implies the agent has some kind of objective.
- The environment is not fully known to the agent and may contain surprises and new situations that have not been anticipated in advance. To offset this, the agent uses learning, adaptation and experimentation.
- As a measure of intelligence, the agent is able to learn and adapt so as to perform well over a range of specific environments.
Legg and Hunter then provide a concise definition of intelligence that summarise these aspects [2]:
Intelligence measures an agent’s ability to achieve goals in a wide range of environments.
The current successes in Machine Learning, although really remarkable on their own, fail short in this generality and are restricted to the confines of a specific problem in a particular environment. Even breakthrough work like the one presented by Mnih et.al. [3] that showed a single model being able to adapt to a multitude of Atari games (49 to be more precise), does not provide a truly general model.
For our General AI we will therefore need to define an all-encompassing Environment and Problem that will contain all sub-environments and problems that the Agent is faced with.
Our aim is to consider the largest possible Environment, the Universe. This way there can be no intrinsic limitation built into the model. I will continue to use the term 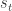
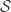
Similar to the policy 
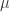
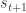
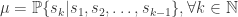
I will not dwell too much at this time about this definition, for the time being the important thing to remember is that there are some rules behind the evolution of the Environment that our Agent will aim to infer in order to solve The Problem.
Speaking of The Problem, we can formulate it as well in a very simple way: “Solve
When RL models are build and run, the goal is provided by the programmer. This is suitable for localized problems, where we can define a specific scope for the problem at hand, but this will not be possible for the ultimate goal of a General AI model. I will assert that this goal (“solve
References:
[1] S. Legg, M. Hutter: A collection of Definitions of Intelligence, 2007
[2] S. Legg, M. Hutter: A Formal Measure of Machine Intelligence, 2006
[3] V. Mnih et. al.: Human-level Control Through Deep Reinforcement Learning, 2015
[4] P.S. Laplace: A Philosophical Essays on Probabilities
[5] S. Hawking: Does God Play Dice? Public Lecture, 2000
This post is part of a series “The Quest for General Artificial Intelligence”. To access the index for this series click here.
