This post is part of a series “The Quest for General Artificial Intelligence”. To access the index for this series click here.
Reinforcement Learning (RL) is an exciting approach to Machine Learning (ML) that has gained significant attention in the last years due to a number of remarkable achievements, culminating with the DeepMind’s success against Lee Sedol in 2016. What makes RL particularly attractive is the fact that it seems to provide a mechanism to learn behaviour without any intervention from outside, and it is very common in the literature to see the expression “on its own” being used to describe the learning process that a given model goes through in order to produce a particular desired behaviour.
While this is true to a large degree, there are elements in our current “classical” RL model that make it limited by design and dependent on arbitrary decisions taken by the programmer. This is not compatible with the idea of a General AI that would equal or surpass human abilities in a general way.
I will try to introduce a number of fundamental changes to the classical Reinforcement Learning model that, at least in my opinion, will remove some of these self-imposed limitations and free the model towards a level of generalisation that we all in the AI community aspire to.
I will start by presenting the current formal representation of a RL model, as introduced by Sutton and Barto in 1998 [1].
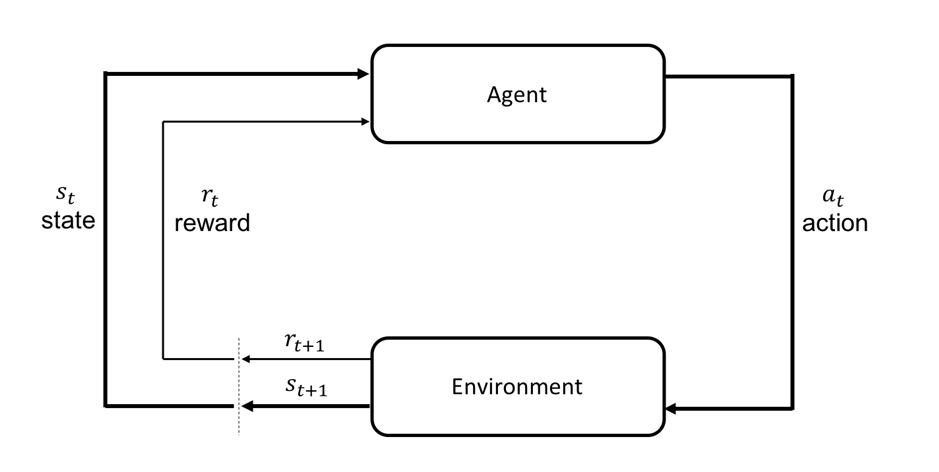
The model assumes an Environment and an Agent. The Agent is that part that we want to exhibit “intelligent” behaviour while the Environment is everything else outside this Agent. The Environment is described by a State at a given point in time 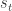


The purpose of a RL model is to maximize the total Reward over a period of time (and the fine print of the actual model implementation decides about what this “period of time” might be and if the rewards received are subject to any time decay, etc.). This is in general represented by a Policy 

All models and algorithms apply different techniques to determine this
Despite recent advances in the use of RL for solving complex ML problems, it is still the case that:
- RL models are limited to defined tasks and there is very little advance towards a General Intelligence
- State space dimensionality has an exponential impact on the performance of the model and trying to tackle general problems soon becomes prohibitively complex
- The models are very slow to train and seem to lack the “human intuition” when it comes to interpreting rewards
- The actions taken by the Agent are assumed to actually happen in the Environment and the stochastic nature of the actual outcomes of these actions is rarely considered
In the following sections I will introduce a number of changes to the classical Reinforcement Learning model that, in my view, will help overcome these limitations and formalise a more general representation of the problem.
References:
[1] R. Sutton, A. Barto: Reinforcement Learning: An Introduction, 1998
This post is part of a series “The Quest for General Artificial Intelligence”. To access the index for this series click here.
